智能医学图像计算重点实验室的罗月梅老师及团队一直致力于OCT成像与分析以及深度学习自动识别算法的研究。近期,罗老师及团队提出了一种新的半监督学习(SSL)方法,将类别感知对比学习与FixMatch相结合,使用最少的标记数据增强视网膜疾病识别的鲁棒性和精度。该研究成果(Retinopathy Identification in Optical Coherence Tomography Images Based on a Novel Class-Aware Contrastive Learning Approach(基于新型类别感知对比学习方法的光学相干断层扫描图像中的视网膜病变识别))最近被Knowledge-Based Systems(中科院一区期刊,杂志最新影响因子7.2)录用。罗月梅老师为本文通讯作者,重点实验室研究生李源为第一作者。
研究背景
计算机视觉技术在基于光学相干断层扫描(OCT)图像的视网膜疾病检测中发挥了重要作用。然而,这通常依赖于可能稀缺的大型标记数据集。检测视网膜疾病面临具体挑战,例如需要准确区分各种细微的疾病特征,以及需要大量标记数据,这些数据通常难以获得且昂贵。此外,手动注释视网膜图像是劳动密集型的,容易出现人为错误。半监督学习,特别是通过伪标记,有望利用未标记的数据;然而,它并不总是能够抵制确认偏误。
1.简介
以往的研究存在以下不足:首先,伪标签精度的生成极大地影响了模型质量,其次,确认偏差会损害未知数据的一致性约束,从而影响模型的性能,另外,模型训练可能需要大量的标记数据。
为了解决上述不足之处,本文提出了一种新的半监督学习(SSL)方法,将类别感知对比学习与FixMatch相结合,使用最少的标记数据增强视网膜疾病识别的鲁棒性和精度,消除了对额外注释和领域知识的需要。
为了对复杂视网膜病变OCT图像的确认偏差进行鲁棒的预测,本文从分布外数据中构建了一个选择的矩阵,并根据预测分数重新加权预测,这可以识别偏差并优先考虑干净的数据,从而减少过度拟合到可能不正确的伪标签。本文计算了特征和加权矩阵之间的监督对比损失,以捕获细微的类关系。这有助于建立比传统交叉熵损失训练的模型更有辨识力的模型。
2.方法
图1是本论文的算法流程图,可分为以下步骤:
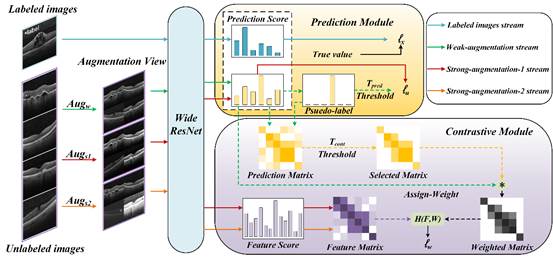
图1 算法流程图
首先给定一批有标记和未标记的图像,将有标记的图像传递给预测模块,得到 。
。
然后,预测模块接收弱增强和强增强的未标记图像,并计算出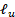 。
。
随后,对比模块利用弱增强图像生成的伪标签,通过图像级对比学习构建一个选择矩阵,以减少确认偏差。通过重新加权,优先处理干净的数据,得到加权矩阵。利用两类强增强的图片构造特征矩阵,计算出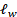 。
。
最后将上述三种损失进行加权组合,计算公式如下: 。
。
注意: 模型有逻辑值和特征值两个输出。实线表示特征值或逻辑值,虚线表示通过softmax映射得到预测分值后的逻辑值。
3.实验结果
为了评估算法,本文使用了三个经典的视网膜病变数据集。
第一个数据集BOE是由杜克大学的Srinivasan等人提出的。BOE数据集包含AMD、DME和NORMAL三个图像类别,共收集了45个受试者,其中AMD、DME和NORMAL类别的图像分别为723、1101和1407张,共计3231张图像。
第二个数据集是RetinalOCT,最初由Subramanian等人引入。原始数据集包括八种不同的视网膜病变类型。在本研究中,本文主要关注三个子集:AMD、DME和NORMAL。每个类别包含3000张图像,总共9000张OCT图像。
第三个数据集CELL来自2013年7月1日至2017年3月1日在美国加州大学圣地亚哥分校Healey眼科研究所、视网膜研究基金会、医学中心眼科协会、上海第一人民医院和北京同仁眼科中心的成人患者回顾性队列。该数据集包含四个图像类别:CNV、DME、DRUSEN和NORMAL。CNV、DME、DRUSEN和NORMAL类别中分别有37,447、11,590、8,858和26,557张图像,总共有84,452张图像。
图2显示了三个数据集不同病变的代表性图像。
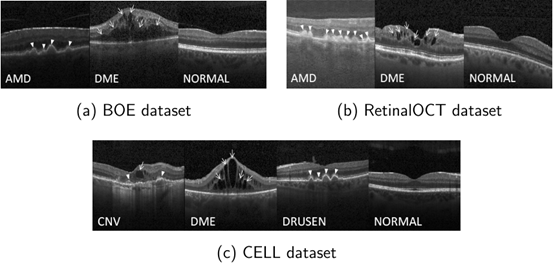
图2本论文所使用的数据集样本示例
实验结果如表1-3所示。很明显,SSL方法在分类效率方面大大优于传统的监督学习方法。值得注意的是,本文专有的类别感知对比学习技术作为一种卓越的方法脱颖而出,优于所有其他指标,在BOE、RetinalOCT和CELL数据集上分别实现了0.966、0.964和0.957的准确率,0.966、0.964和0.957的灵敏度,以及0.983、0.982和0.986的特异性。此外,p值结果提供了明确的证据,证明所提出的方法优于现有的方法。
表1 BOE数据集上的实验结果
Method |
Accuracy |
STD |
P-value |
Sensitivity |
Specificity |
SVM+HOG |
0.570 |
- |
2.40E-18 |
0.570 |
0.785 |
CNN |
0.802 |
0.067 |
7.30E-04 |
0.802 |
0.901 |
ResNet-18 |
0.601 |
0.046 |
1.28E-06 |
0.601 |
0.800 |
ResNet-18+Pretrain |
0.840 |
0.022 |
1.12E-05 |
0.840 |
0.920 |
AlexNet |
0.523 |
0.032 |
1.20E-09 |
0.523 |
0.761 |
AlexNet+Pretrain |
0.754 |
0.017 |
1.97E-08 |
0.754 |
0.877 |
VGG-16 |
0.629 |
0.059 |
8.84E-07 |
0.629 |
0.814 |
VGG-16+Pretrain |
0.855 |
0.025 |
3.64E-05 |
0.855 |
0.927 |
Pseudo-Labeling |
0.903 |
0.021 |
1.13E-05 |
0.903 |
0.951 |
Temporal Ensembling |
0.894 |
0.049 |
8.88E-04 |
0.894 |
0.947 |
Mean Teacher |
0.926 |
0.038 |
4.04E-04 |
0.926 |
0.963 |
VGG+VAT |
0.942 |
0.024 |
1.53E-02 |
0.942 |
0.971 |
DeFixmatch |
0.937 |
0.007 |
3.34E-06 |
0.937 |
0.969 |
SoftMatch |
0.951 |
0.012 |
4.12E-04 |
0.951 |
0.976 |
InfoMatch |
0.922 |
0.004 |
1.84E-07 |
0.922 |
0.961 |
Proposed |
0.966 |
0.002 |
- |
0.966 |
0.983 |
表2 RetinalOCT数据集上的实验结果
Method |
Accuracy |
STD |
P-value |
Sensitivity |
Specificity |
SVM+HOG |
0.806 |
- |
1.00E-12 |
0.806 |
0.903 |
CNN |
0.789 |
0.009 |
3.28E-10 |
0.789 |
0.894 |
ResNet-18 |
0.821 |
0.027 |
9.49E-07 |
0.821 |
0.910 |
ResNet-18+Pretrain |
0.870 |
0.022 |
5.71E-06 |
0.870 |
0.935 |
AlexNet |
0.633 |
0.102 |
4.35E-05 |
0.633 |
0.817 |
AlexNet+Pretrain |
0.835 |
0.053 |
3.67E-05 |
0.835 |
0.918 |
VGG-16 |
0.809 |
0.032 |
2.69E-06 |
0.809 |
0.904 |
VGG-16+Pretrain |
0.908 |
0.017 |
5.18E-05 |
0.908 |
0.954 |
Pseudo-Labeling |
0.899 |
0.013 |
5.62E-05 |
0.899 |
0.950 |
Temporal Ensembling |
0.918 |
0.012 |
2.17E-04 |
0.918 |
0.959 |
Mean Teacher |
0.931 |
0.008 |
2.72E-05 |
0.931 |
0.966 |
VGG+VAT |
0.937 |
0.006 |
3.44E-05 |
0.937 |
0.969 |
DeFixmatch |
0.953 |
0.016 |
1.64E-02 |
0.953 |
0.977 |
SoftMatch |
0.950 |
0.007 |
4.75E-03 |
0.950 |
0.975 |
InfoMatch |
0.930 |
0.005 |
2.86E-06 |
0.930 |
0.965 |
Proposed |
0.964 |
0.004 |
- |
0.964 |
0.982 |
表3 CELL数据集上的实验结果
Method |
Accuracy |
STD |
P-value |
Sensitivity |
Specificity |
SVM+HOG |
0.522 |
- |
4.46E-19 |
0.522 |
0.841 |
CNN |
0.556 |
0.036 |
2.61E-08 |
0.556 |
0.852 |
ResNet-18 |
0.569 |
0.033 |
1.35E-08 |
0.569 |
0.856 |
ResNet-18+Pretrain |
0.826 |
0.033 |
1.82E-05 |
0.826 |
0.942 |
AlexNet |
0.432 |
0.023 |
8.62E-11 |
0.432 |
0.811 |
AlexNet+Pretrain |
0.837 |
0.027 |
2.45E-06 |
0.837 |
0.946 |
VGG-16 |
0.527 |
0.054 |
1.09E-07 |
0.527 |
0.842 |
VGG-16+Pretrain |
0.844 |
0.022 |
3.64E-06 |
0.844 |
0.948 |
Pseudo-Labeling |
0.916 |
0.017 |
1.42E-04 |
0.916 |
0.972 |
Temporal Ensembling |
0.866 |
0.021 |
3.14E-05 |
0.866 |
0.955 |
Mean Teacher |
0.883 |
0.041 |
1.45E-02 |
0.883 |
0.961 |
VGG+VAT |
0.936 |
0.007 |
8.88E-05 |
0.936 |
0.979 |
DeFixmatch |
0.936 |
0.006 |
3.33E-05 |
0.936 |
0.979 |
SoftMatch |
0.943 |
0.004 |
1.37E-05 |
0.943 |
0.981 |
InfoMatch |
0.866 |
0.003 |
2.61E-11 |
0.866 |
0.955 |
Proposed |
0.957 |
0.002 |
- |
0.957 |
0.986 |
图3显示了所有对比方法的ROC和PR曲线。可以看出,所提出的方法优于比较中涉及的所有其他方法,这一发现与表1-3所示的指标一致。

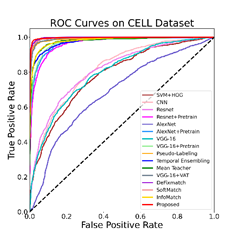
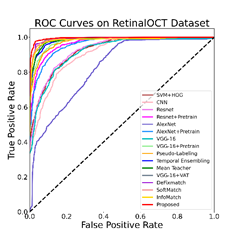
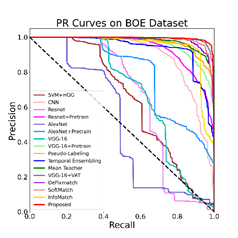
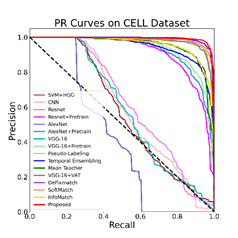

图3 对比实验结果的ROC和PR曲线
本论文的方法的混淆矩阵如图4所示。很明显,本文的方法对NORMAL和AMD类产生了很高的分类精度。然而,DME的识别准确率略低,这可以归因于DME样本的稀缺性和病变区域极小的样本的存在。尽管如此,本文的方法的总体性能还是非常优秀的。
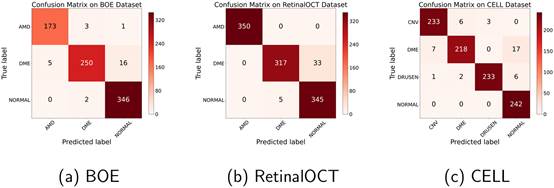
图4 本论文算法在三个数据集上的混淆矩阵
在本论文中,CELL数据集包含由Kermany等人组织的6位人类眼科专家注释的1000张OCT图像。本文将所提出的方法结果与人类专家的结果进行了比较,如图5所示。为了评估所提出方法的鲁棒性,本文使用不同数量的标记图像(80和160)来训练本文的模型。实验结果表明,本文的模型可以提供与人类专家相当的性能。事实上,只有80张标记图像,本文的模型比两位专家表现得更好(专家达到了92.1%的最低准确率)。本文的模型有160张标记图像,超过了大多数人类专家。这些发现证明了本文的方法在临床诊断中的可靠性。
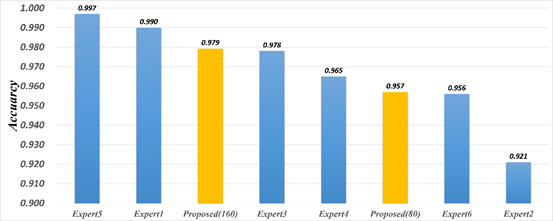
图5 本论文提出的方法与人类专家的准确率比较
总结
本论文提出了一种基于OCT图像的视网膜疾病检测的半监督学习方法。该方法结合了用于原始OCT图像特征提取和学习的WideResNet网络,以及两个创新的下游模块:预测模块和对比模块。本文设计了一个类别感知的对比学习框架来权衡传统的监督、半监督和对比学习损失,避免确认偏差并提高模型性能。实验结果表明,该方法在BOE、RetinalOCT和CELL数据集上分别只需要55张、102张和80张标记OCT图像进行训练,准确率分别达到0.966、0.964和0.957。这证明了利用OCT图像检测视网膜疾病的有效性。
智能医学图像计算重点实验室的研究团队汇聚了来自医学、工程等多个领域的专家和学生,凭借各自的专业背景与知识,共同致力于解决医疗行业中的关键问题。医工交叉的团队结构使得他们能够从不同角度整合资源,推动医疗技术的创新与应用,进而提升诊疗效率和质量,推动医疗事业的不断发展。该项研究展示了半监督学习在视网膜疾病检测中的潜力,且为未来的研究探索提供了全新的方向。在本研究工作中,研究人员通过将类别感知对比学习与FixMatch方法相结合,成功地在标注数据极为有限的情况下,实现了高精度的视网膜疾病识别。这项技术不仅有效降低了人工标注的工作量,还为临床诊断提供了有力的支持。随着更多数据的积累和更先进算法的不断涌现,智能医学图像计算领域将不断进步,推动医疗行业实现更多的突破与创新。




