研究背景
深度学习在医学影像分析中展现了巨大潜力,尤其是在基于光学相干断层扫描(OCT)的视网膜病变分类任务取得了巨大成功。然而,深度学习模型在基于OCT图像的视网膜疾病诊断仍面临许多挑战。例如,目前经典的深度学习方法将图像视为网格或序列结构,这种结构会限制捕捉不规则和复杂的对象,从而降低了灵活性。此外,不同医疗机构的OCT设备因光源波长、探测器灵敏度及成像模式的差异,导致图像分布存在显著差异(域偏移),严重制约深度学习模型的泛化性能。
智能医学图像计算江苏高校重点实验室罗月梅老师研究组致力于OCT成像和深度学习自动识别算法的研究。针对上述问题,罗月梅老师指导本科生分别提出了一种新的基于金字塔视觉图卷积网络(PVGCN)的视网膜疾病分类方法,以及基于域对抗图卷积网络(DAGCN)的跨域视网膜疾病分类方法。研究成果《基于新型金字塔视觉图卷积网络的OCT视网膜疾病分类(Classifying Retinal Diseases via a Novel Pyramid Vision Graph Convolutional Network for Optical Coherence Tomography Images)》近期被中科院二区期刊《Biomedical Optics Express》录用,论文中提出的PVGCN通过构建新颖的图结构表示和金字塔结构,在实现高精度分类的同时降低了计算成本。DAGCN模型针对跨域分类问题,通过融合数据结构感知对齐与类中心对齐模块,显著提升跨域视网膜病变分类的鲁棒性。相关的研究成果《基于光学相干断层扫描传感器的跨域视网膜病变分类(通过域对抗图卷积网络)(Cross-Domain Retinopathy Classification Based on Optical Coherence Tomography Sensors via Domain Adversarial Graph Convolutional Network)》也已发表于中科院二区期刊《IEEE Sensors Journal》。这两篇论文的第一作者分别是钱瑾和陶磊同学,他们都来自南京信息工程大学人工智能学院人工智能专业2021级2班。
论文一:《基于新型金字塔视觉图卷积网络的OCT视网膜疾病分类》
1.简介
针对 OCT 视网膜病变分类问题,现有的深度学习方法在处理 OCT 图像上的效率仍面临若干关键性技术挑战:首先,使用不同的结构处理OCT 图片的效果不同,导致灵活度不够;其次,常规的基于邻居信息图卷积神经网络(GCN)在每一轮迭代更新过程中导致特征信息逐渐传播并趋同化存在过平滑的问题,从而导致性能较差。另外,各向同性结构在处理 OCT 图像时不区分不同尺度的信息,这样的作法会忽视了不同组织结构之间的自然生理上的差异,无法详细灵活地充分捕捉图像中的信息。
为了解决上述不足之处,我们提出了一种金字塔架构的PVGCN,通过改进的图卷积块来不断聚合和更新图中各节点和邻居节点的信息,使视网膜组织结构之间的位置信息更加紧密联系。并且添加了 FFN 对节点的特征进行非线性转换和利用残差连接,这样可以缓解层坍塌和过平滑现象的同时实现了高精度视网膜病变分类。
为了对复杂视网膜病变OCT图像进行充分的信息理解,采用了渐进缩减的金字塔架构,这种方式将OCT 视网膜图像分解为多尺度的子图进行处理,可以提取不同尺度的信息进行融合,提高了全局视野。同时渐进缩减的策略可以减少计算量。这种处理方式使得 PVGCN 更加灵活逐级提取信息,更有效地理解和利用信息,更好地识别出视网膜中不同的组织结构。
2.方法
图1是本论文的算法流程图,可分为以下步骤:

图1:算法流程图
如图1所示,我们展示了OCT病例图像完成病例分类的流程。以AMD,DME和NORMAL为例,我们首先在Image instantiation部分将三种不同类型的OCT数据集中的图片切割为节点,然后各节点建立连接形成图结构。其中对于图结构的构建,我们将大小为H×W×3的图像划分为N个块,并将其转换为特征向量,最终我们连接各个节点获得了Graph,如步骤一所示。
在步骤二中,通过上述步骤将图像输出为图形数据X,我们将X输入trained model部分,X首先进入含有多个Vision Graph模块的PVGCN中,然后使用由具有图卷积的Grapher模块和具有两个线性层的FFN模块组成的Vision Graph块进行聚合和更新图信息和节点特征变换,在特征提取的过程中,每个FFN模块之后添加一个Downsample块用来实现尺度缩减。随着层数的加深不断缩小提取空间尺寸,最终形成渐进缩减的金字塔结构,在这一训练过程中根据lose值L训练模型。
在步骤三中,我们将测试集数据输入训练好的模型以进行预测,完成视网膜病变分类任务。
3.实验结果
在本研究中共使用了两个视网膜病变数据集,分别为BOE数据集和CELL数据集。
实验结果如表1-2所示。通过实验结果可以看出,PVGCN 在 BOE 和 CELL 数据集上的性能都优于所有其他对比的基准方法。这表明了 PVGCN 在利用 OCT 图像检测视网膜病变方面的有效性。此外,我们所提出的 PVGCN 方法在两个数据集上的准确率分别为 0.9954 和 0.9787,精确度分别为0.9918和0.9650,召回率分别为0.9877和0.9555,F1分别为0.9896和0.9602,由此可以得出 PVGCN 显著优于所有基准方法,在这两个数据集中表现优异。
表3分别使用原始数据集的0.8、0.5、0.2、0.1、0.05 的数据量对这些方法进行训练,最后得出不同比例的数据,当数据量逐渐减少,几种方法间的差异逐渐明显,当数据量取0.05(约 4224 张 OCT 图像)时,算法的准确率之间的差异最大。从最终结果可以看出PVGCN 比 VGG-16 高了将近三个百分点。因此我们可以得出,PVGCN 在 BOE 和 CELL数据集上的性能优于其他几种方法。
表1: BOE数据集上的实验结果
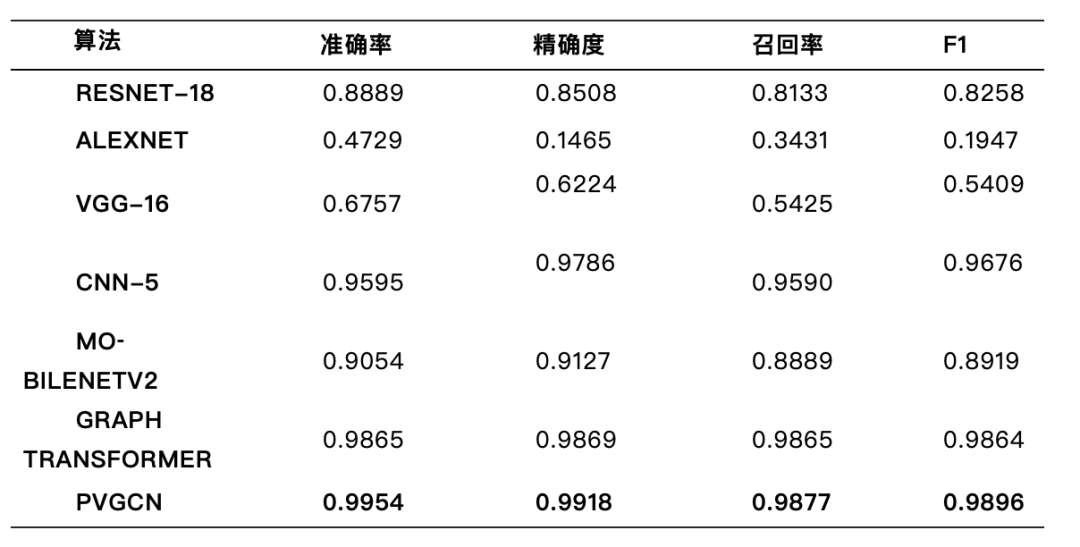
表2: CELL数据集上的实验结果

表3: 不同比列CELL数据集上的实验结果

表4-5显示了PVGCN组成模块的效果。从实验结果可以看出,取消全连接层(FC)和 前馈神经网络(FFN)模块直接使用GCN 进行训练效果变差,缺少 FC 和 FFN 会导致特征表达能力下降。接下来只引入 FC 之后结果显示精度得到了提升,在此基础上继续添加FFN模块,最终得到的良好的效果。这表明这些模块在 PVGCN中起着重要作用,增加了更多的特征转换。同时我们对比了改进之后的视觉图块(Vision Graph)和金字塔结构对于实验精度的影响。从中可知,改进之后的视觉模块对比未改进的模块精度从 0.9774 提升到 0.9909。我们验证了金字塔结构对 PVGCN 模型的性能优势,采用金字塔结构的PVGCN可以达到0.9954的准确率,较采用各向同性的PVGCN准确率达到0.9909,在性能有所提升。通过上述实验数据表明,Vision Graph块与金字塔结构对模型的精度提升起到了重要作用。
表4: 图卷积中不同组件的对比效果
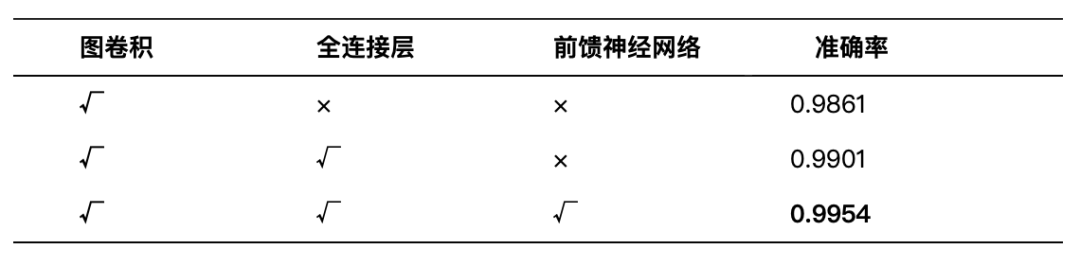
表5: PVGCN不同组件的对比效果
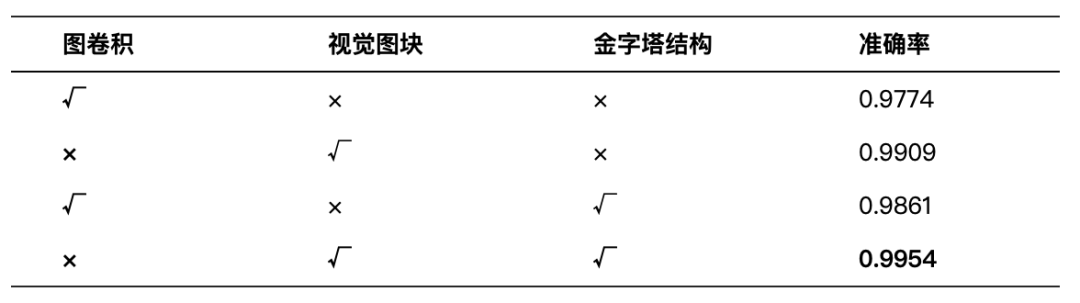
表6我们分别采用了只是用一层尺度,结合一层和二层尺度,结合前面三层尺度和结合全部四种尺度的信息,来进行实验证明。实验结果呈现出明显的性能差异:在准确率的对比上,从一层尺度的0.5638至四尺度的0.9787,得到了很明显的提升。在精确率、召回率和F1分数这些对比参照指标上,也体现出不同尺度信息结合对于性能显著提升的趋势。表7展示了CELL数据集上的优化后性能指标。与原始结果相比,平衡训练后的模型准确率,精确度和F1这些指标上会出现小幅度的提升,同时召回率出现小幅度的下降。上述实验结果表明,经过类别平衡策略确实可以有效提升模型对少数类样本的检测能力,在具体的实验中的差距不是很大,不影响整体性能
表6: 不同尺度的对比效果

表7: 基于数据增强的类别平衡策略对PVGCN模型在CELL数据集上性能的影响分析

构建图时邻居数量K作为控制聚合范围的超参数,其合理数值代表相邻节点数量,不同K值对信息交换程度影响较大,分析同一数据在不同K值下对准确度的影响,具体实验中,K分别取值3、6、9和12,并于表8展示相应实验结果。结果说明,邻居节点数量在9至12之间时,分类任务执行效果良好,为兼顾性能与质量,模型设置中选择9作为最终实验参数。
表8: 不同k值条件下的准确度影响

本论文的方法的混淆矩阵如图2所示。很明显,我们的方法对NORMAL和AMD类产生了很高的分类精度。然而,DME的识别准确率略低,这可以归因于DME样本的稀缺性和病变区域极小的样本的存在。尽管如此,我们的方法的总体性能还是非常优秀的。

图2:本论文算法在两个数据集上的混淆矩阵
在本论文中,CELL数据集包含由Kermany等人组织的6位眼科眼科专家注释的1000张OCT图像。所提出的PVGCN 方法在CELL 数据集测试中表现出色。图3中其中眼科专家最高准确度可以达到 0.997,最低的准确度约为 0.921。PVGCN 方法的准确度在眼科专家中排名前三,这可以证明我们提出的 PVGCN 方法可以达到了眼科专家的水平。
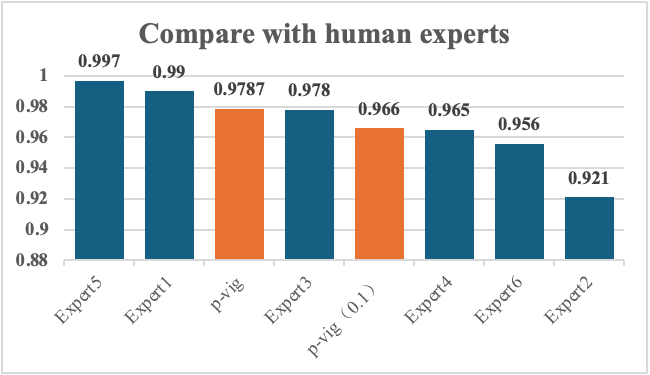
图3:本论文提出的方法与眼科专家的准确率比较
总结
在本文中,我们提出了一种用于视网膜疾病识别的新型金字塔结构视觉神经网络模型 (PVGCN)。该模型使用将Grapher 模块和FFN 模块组合为基本单元的Vision Graph 模块,采用图形卷积技术来聚合和更新图形信息,并结合非线性变换来解决图像中的过度平滑问题。PVGCN 逐渐缩小的金字塔结构更好地利用了图结构的特点,自然而然地从多个尺度捕捉了各种结构之间的联系。此外,通过采用空间缩减,减少了计算资源的消耗,使PVGCN 更加轻量级。在两个流行的OCT 数据集(BOE 和CELL)上,PVGCN 分别取得了0.9954 和0.9787 的最佳结果,超过了其他比较的深度学习方法。此外,在CELL 数据集上,PVGCN 网络达到了顶级眼科专家的水平。
论文二:《基于OCT传感器的跨域视网膜病变分类(通过域对抗图卷积网络》
1.简介
现有域适应方法存在着局限性:首先是对于数据结构的忽视,传统域适应方法依赖全局统计对齐,从而忽略了图像局部结构关系;其次是类别语义的偏差,仅依赖标签信息的方法通常易受噪声干扰,导致类别特征混淆;还有就是计算效率上的不足,复杂的对齐策略反而会增加模型复杂度,导致难以满足临床实时需求。
为了解决上述问题,本研究创新性提出DAGCN框架,核心贡献如下:第一点是使用数据结构感知对齐模块,通过利用图卷积网络(GCN)构建实例图,捕获OCT图像的局部结构信息,减少域间几何偏移;第二点是使用类中心对齐模块,通过缩小源域与目标域同类别特征中心距离,增强跨域语义一致性;此外,本研究通过多损失联合优化,结合对抗损失、熵最小化损失与域相似性损失,实现高效域不变特征学习。
2.方法
DAGCN方法流程如图4所示,分为三步:

图4:基于DAGCN 光学相干断层扫描的跨域视网膜病变分类方法概述
DAGCN共包括三个步骤,在步骤一中,我们首先使用源域数据训练源域特征提取器和分类器,并通过交叉熵损失和数据结构感知对齐损失来引导源域特征提取器和分类器的训练,其中数据结构感知对齐损失由源域数据训练源域特征提取器中生成的结构分数计算得到;
在步骤二中,我们使用源域特征提取器的权重初始化目标特征提取器。值得注意的是,此时
是固定的,在此步骤中不需要更新。然后,我们利用对抗损失、熵最小化损失、域对抗相似损失以及类质心对齐损失对及进行训练,而对于判别器,我们也使用一个交叉熵损失引导其训练;
在最后的步骤三中,我们使用目标特征提取器和分类器对目标域数据进行推理预测。
3.实验结果
本研究在三个公开OCT数据集(BOE记为A、TMI记为B、CELL记为C)上验证DAGCN性能,涵盖三种跨域场景(A→B、A→C、B→C),实验结果如下:
表9: 各方法不同跨域场景下的分类实验结果
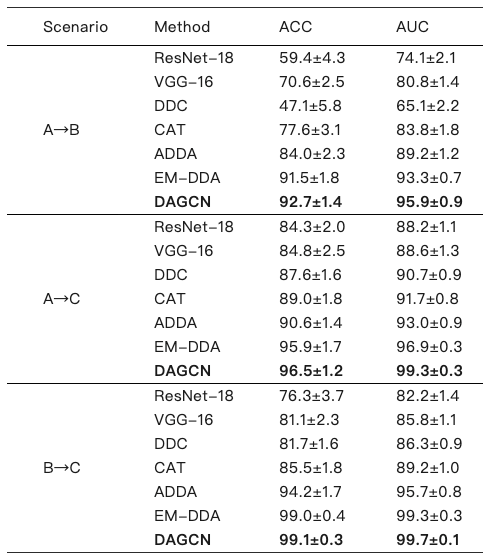
实验表明,DAGCN在三种场景下的分类准确率分别达92.7%、96.5%和99.1%,显著优于ResNet-18、ADDA等基准方法(如表9所示)。此外,DAGCN推理速度较次优方法(EM-DDA)提升22%-25%,单图像处理仅需4ms,满足临床实时需求(结果见表10)。
表 10: 各方法不同跨域场景下的推理时间

表11: 消融实验结果
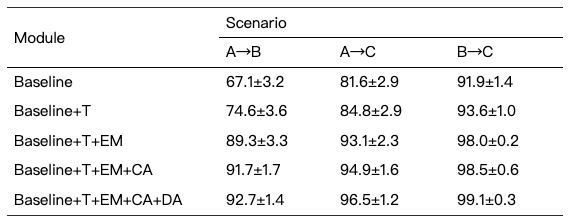
通过消融实验(如表11所示),本研究证明了设计的所有模块均对OCT图像的跨域分类起到了显著作用。
本研究对方法中使用到的几个重要参数也进行了敏感性分析,其结果如图5所示。我们的方法中有5个重要的超参数,也称权重平衡参数。敏感性分析表明,模型对λ变化不敏感,但其仍然能够略微提升模型的性能,而γ的适度增大可提升性能,过量则因过度类别压缩导致性能下降。

a、A→B场景下

b、A→C场景下
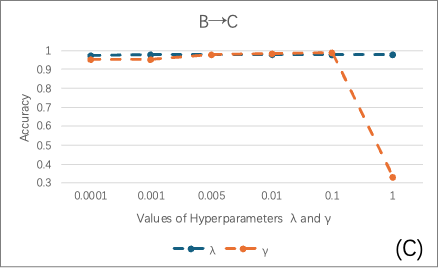
c、B→C场景下
图5:三种场景下超参数和在不同值下对模型性能的影响
此外,通过t-SNE特征可视化(如图6所示)可见,DAGCN有效对齐源域与目标域数据分布,并增强类别间可分性,而基线方法(无域适应)则存在明显域间差异。

(a) Baseline: A→B; (b) EM-DDA: A→B; (c) DAGCN: A→B
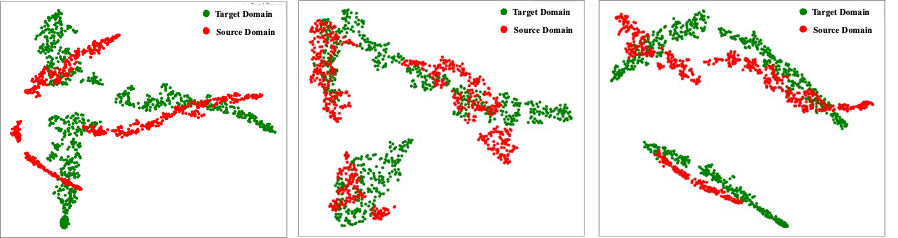
(b) Baseline: A→C; (b) EM-DDA: A→C; (c) DAGCN: A→C

(c) Baseline: B→C; (b) EM-DDA: B→C; (c) DAGCN: B→C
图6:跨域任务A→B、A→C、B→C 中的T分布随机邻域嵌入(t-SNE)可视化
与眼科专家对比,在数据集C上,DAGCN在B→C场景中的准确率(99.1%)超越4位眼科专家,与最优专家持平;A→C场景准确率(96.5%)亦优于3位专家。这一结果凸显其辅助诊断潜力。
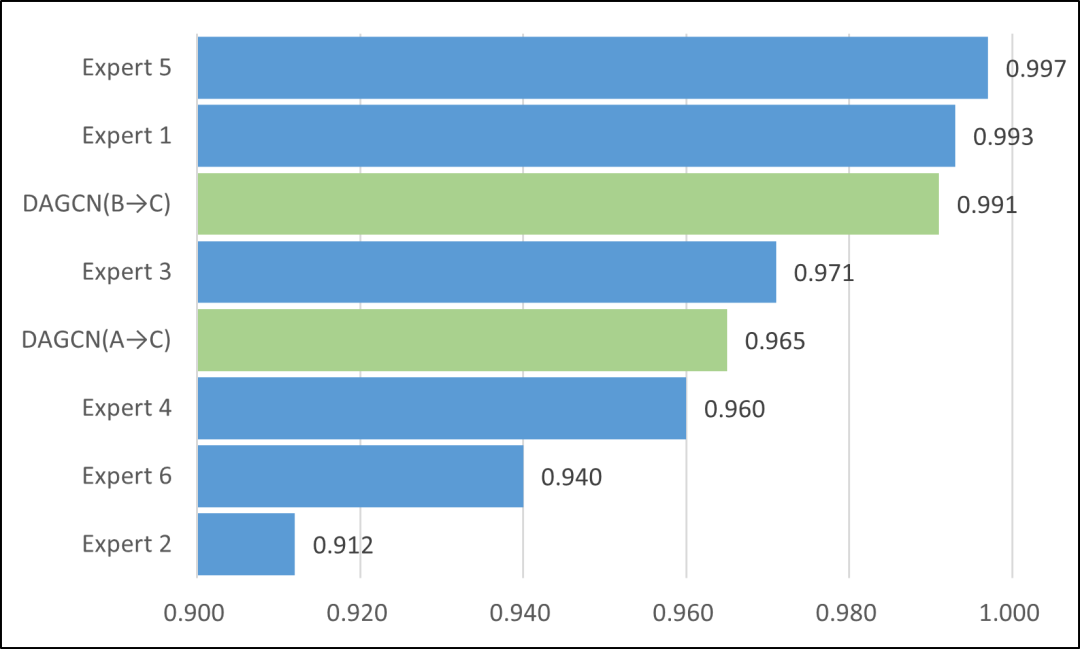
图7:与眼科专家的分类精度对比
总结
本文提出了一种用于光学相干断层扫描(OCT)图像视网膜病变分类的域对抗图卷积网络(DAGCN),通过两个创新模块显著提升跨域分类性能:第一个是结构感知对齐模块,通过数据结构分析器和特征提取器的多层次融合构建密集连接的实例图,作为图卷积网络输入;第二个是类质心对齐模块,利用类别标签渐进式优化目标域与源域的类别质心距离,增强无监督域适应能力。
实验表明,DAGCN在三组跨域场景下的分类准确率分别达92.7%、96.5%和99.1%,优于对比方法,且可视化结果验证了其特征的类内聚集和类间分离优势。这说明DAGCN攻克了OCT图像跨域分类中的域偏移难题,仅需少量标注数据即可实现高精度、高效率的视网膜病变诊断。并且,该方法在多项指标上达到或超越眼科专家水平,为临床异构设备间的智能诊断提供了可靠解决方案。当然,本研究依然存在一些可以改进的地方,如需提升模型在极端成像条件(如不同设备/协议)和类别不平衡(如罕见病变)下的鲁棒性。未来,研究组将进一步探索其在多模态医学影像分析中的应用并不断改进,推动人工智能赋能精准医疗。
以下是两篇论文的信息:
[1] Jin Qian, Lei Tao, Changhao Gong, Jun Xu, and Yuemei Luo*, “Classifying Retinal Diseases via a Novel Pyramid Vision Graph Convolutional Network for Optical Coherence Tomography Images,” Biomedical Optics Express, Accepted, (2025).
[2] Lei Tao, Jin Qian, Changhao Gong, Dingfa Zhang, and Yuemei Luo*, “Cross-Domain Retinopathy Classification in Optical Coherence Tomography Images Based on Domain Adversarial Graph Convolutional Network,” IEEE Sensors Journal, 2(15), 3473-3483 (2025).




